参考博客:https://www.cnblogs.com/savorboard/p/distributed-system-transaction-consistency.html
1、为什么会出现分布式事务,与本地事务有什么区别?
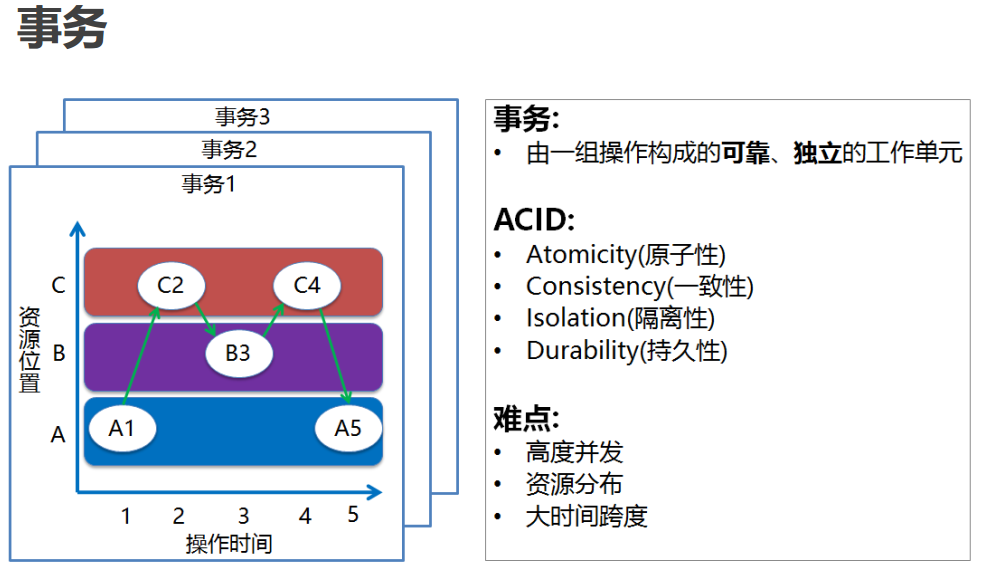


数据库事务: 在开发过程中也会经常使用到。但是即使如此,可能对于一些细节问题,很多人仍然不清楚。比如很多人都知道数据库事务的几个特性:原子性(Atomicity )、一致性( Consistency )、隔离性或独立性( Isolation)和持久性(Durabilily),简称就是ACID。分布式事务: 分布式系统的核心就是处理各种异常情况,这也是分布式系统复杂的地方,因为分布式的网络环境很复杂,这种“断电”故障要比单机多很多,所以我们在做分布式系统的时候, 最先考虑的就是这种情况。这些异常可能有 机器宕机、网络异常、消息丢失、消息乱序、数据错误、不可靠的TCP、存储数据丢失、其他异常等等... 本地事务数据库断电的这种情况,它是怎么保证数据一致性的呢?我们使用SQL Server来举例,我们知道我们在使用 SQL Server 数据库是由两个文件组成的, 一个数据库文件和一个日志文件,通常情况下,日志文件都要比数据库文件大很多。数据库进行任何写入操作的时候都是要先写日志的,同样的道理, 我们在执行事务的时候数据库首先会记录下这个事务的redo操作日志,然后才开始真正操作数据库,在操作之前首先会把日志文件写入磁盘, 那么当突然断电的时候,即使操作没有完成,在重新启动数据库时候,数据库会根据当前数据的情况进行undo回滚或者是redo前滚,这样就保证了数据的强一致性。

2、分布式事务中的CAP理论,BASE理论是什么?

CAP定理是由加州大学伯克利分校Eric Brewer教授提出来的,他指出WEB服务无法同时满足一下3个属性:(至于为什么可以参考上一篇博客)
C:一致性,就是说所有的服务器上面的数据都是一样的,
A:可用性,用户访问服务器上面的数据,响应时间在可以接受的范围内
P:分区容忍性,其实就是高可用性,一个节点崩了,并不影响我们其它的节点
1:满足C,所有的机器上的数据都是一样,这样的情况下会有什么需求呢?每当一个新数据新增到其中一个服务器上,这个数据要同步到其它服务器,这样的情况下才可以保证C
2:满足A,这样的情况下会有什么需求呢?用户随时都在访问,都能在可控的时间内返回正确的数据
3:满足P,非常可靠,怎么能可靠呢?那必须是机器越多越可靠,为啥?我有1亿台服务器,挂了几万台,完全没影响嘛。
BASE理论:
在分布式系统中,我们往往追求的是可用性,它的重要程序比一致性要高,那么如何实现高可用性呢? 前人已经给我们提出来了另外一个理论,就是BASE理论,它是用来对CAP定理进行进一步扩充的。BASE理论指的是:Basically Available(基本可用)Soft state(软状态)Eventually consistent(最终一致性)BASE理论是对CAP中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
3、分布式事务的解决方案以及各个解决方案的优缺点?
(1)基于可靠消息的最终一致性方案

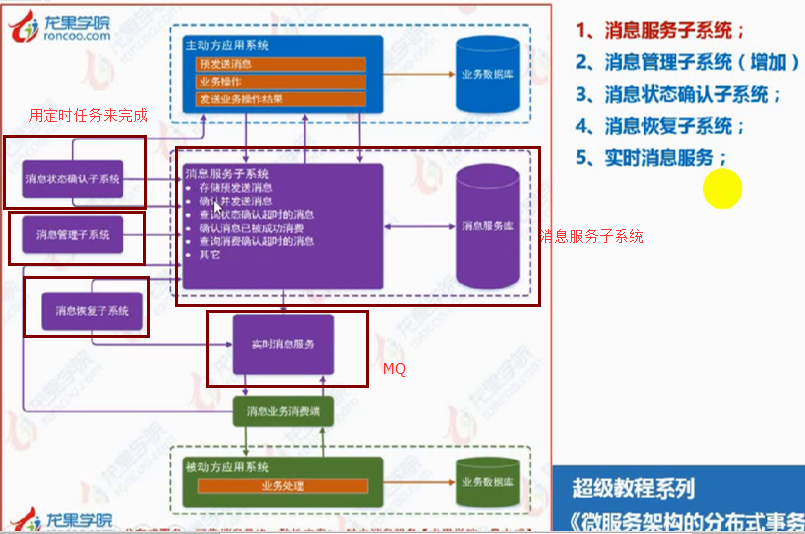

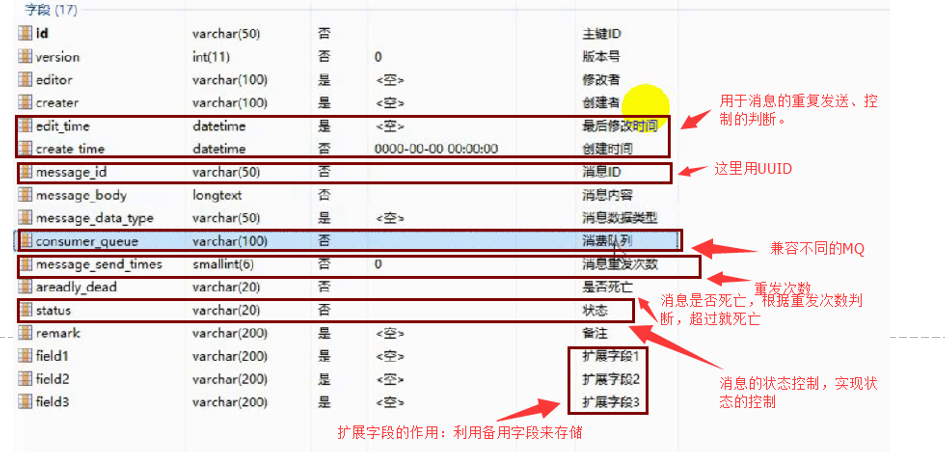
消息表的设计:
(2)TCC补偿方案

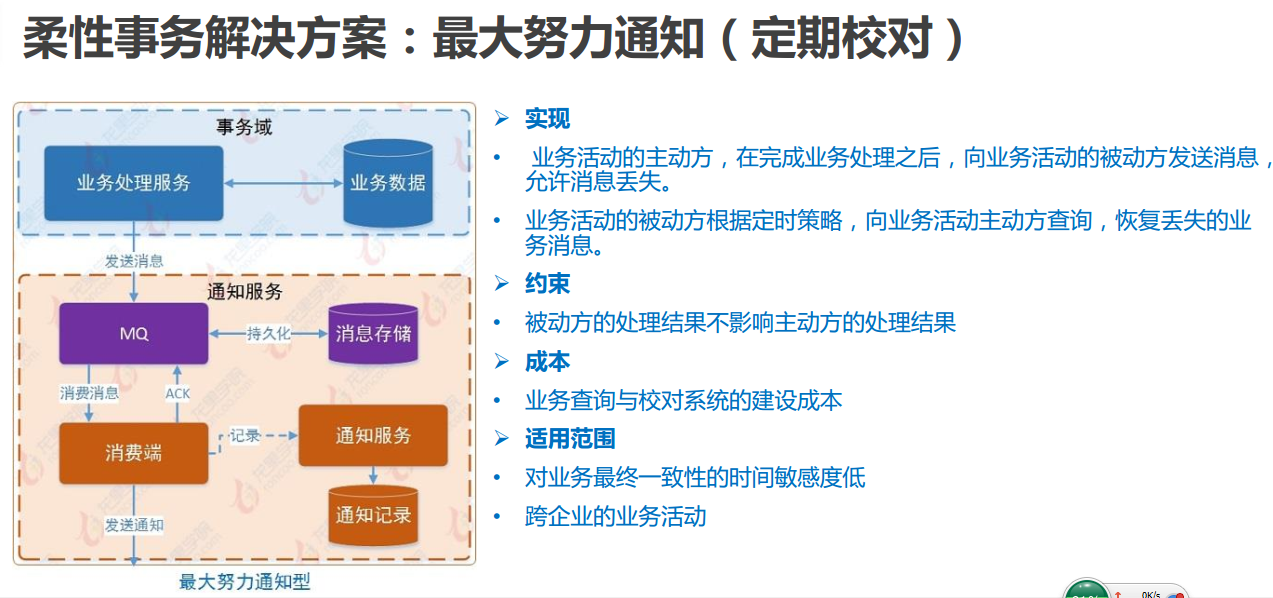
(3)最大努力通知方案